Last week we had our first session of the Algorithmic Machine Learning laboratory, part of the Data Science and Engineering International Master and study track at Eurecom, in Sophia Antipolis, France and we are excited to report that the first in a row of laboratory sessions has been a big success and Zoe + Swarm could easily handle the load generated by our students.

These laboratory sessions use Zoe, a software developed internally, to schedule and deploy a fully configured, ready to use, container cluster based on Jupyter notebooks and Apache Spark.
This set of analytic services is managed by Zoe as an application description: an high level definition of all the processes required to run complex distributed applications.
Zoe uses Docker Swarm to allocate containers: for these laboratory sessions ten server-grade physical hosts are configured with Docker and registered with a Swarm manager. Each user in Zoe is segregated in a separate overlay network and containers are created by Swarm wherever there are available resources.
When a student wants to work on her assignments, she connects to the Zoe web interface and a “Zoe laboratory session application”, composed by a predefined set of containers, is created dynamically for her exclusive use. After a few hours of inactivity the containers are automatically terminated and the resources are freed.
In this post we would like to also highlight a couple of areas where we think Swarm could benefit from more work, especially for the kind of use case we discuss here.
Networking
Accessing overlay networks from outside the Swarm cluster is not easy. Distributed frameworks like Spark, provide a number of interlinked web interfaces that break down when used behind Docker’s port forwarding. Moreover overlay networks use private address spaces that cannot be accessed from the outside without setting up IP routing.
Currently we resort to using a “gateway” container running a SOCKS proxy. Students have to use a browser with the SOCKS proxy configured to access the web interfaces exposed by the containers that are part of Zoe applications.
This solution works well for the web interfaces, but it is far from optimal and we keep looking for possible improvements.
Scalability
The more containers Swarm is managing, the more time it takes to create new ones. Each Zoe application for our laboratory is composed by 5 containers: multiplied by 25 groups of students, we have 125 containers that are created at the beginning of each laboratory session. Since the same Swarm cluster is used also for other activities, when the session starts there are already a few containers running.
In the graph below, we see that the time needed to create a cluster of five containers increases linearly: the first student group had to wait about 7.5 seconds, but the last one 12 seconds. The difference is not big, but noticeable and the trend clear.
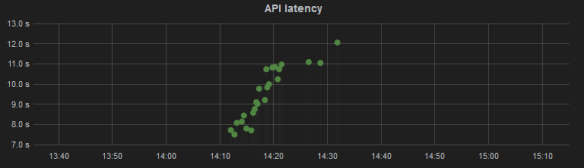
Each point represents the time taken by an API call to start a new application execution in Zoe, so the actual time taken by Swarm to create the 5 containers is smaller. This issue is being discussed on the Swarm issue tracker.
The version of Zoe used for these laboratories is open source and available on github, it is stable and developed more slowly, since it is used in production. We are also working on an experimental version of Zoe, with more advanced concepts in scheduling and dynamic resource allocation.
 red and ready to go.
red and ready to go.